Hadoop MapReduce编程基础及实践指南
在大数据时代,海量数据的处理和分析成为了企业竞争力的关键。Apache Hadoop是一个开源的大型分布式计算项目,它提供了一个框架来解决复杂的数据处理问题。其中,MapReduce是Hadoop核心组件之一,用于高效地对大量数据进行映射(map)和减少(reduce)的操作。本文将详细介绍MapReduce编程基础,并分享一些实践经验。

1. Hadoop MapReduce编程基础
1.1 定义Mapper和Reducer

在MapReduce程序中,最基本的两个概念是Mapper和Reducer。Mapper负责从输入键值对中提取有价值信息并输出新的键值对,而Reducer则负责接收来自多个Mapper输出的同键值对,并合并它们以产生最终结果。
// Mapper类示例
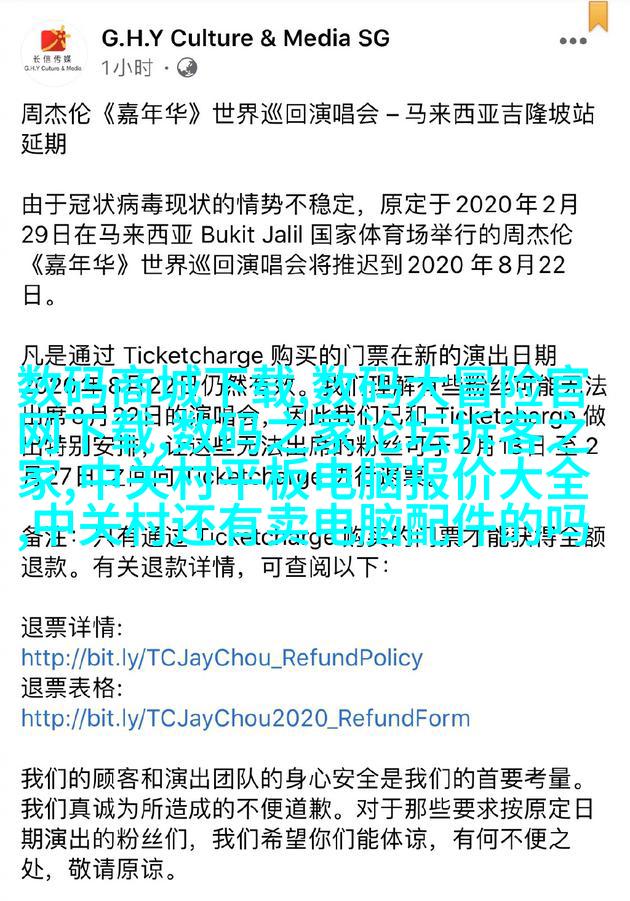
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override

protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
// Reducer类示例
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
1.2 编写Job配置
每个MapReduce作业都需要一个JobConfiger对象来定义它所需的配置。这包括设置输入/输出格式、分发策略以及其他各种参数等。
// Job配置示例
Configuration conf = new Configuration();
// 设置InputFormat及OutputFormat类别名称,以及相应文件路径。
Path inputPath = new Path("input");
TextInputFormat.addInputPath(conf,inputPath);
TextOutputFormat.setOutputPath(conf,"output");
// 创建job实例并设置mapper与reducer类别。
Job job = Job.getInstance(conf,"wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class); // 可选:当集群较小时,可以加快速度。
job.setRedcuerClass(WordCountReducer.class);
// 指定最终输出key类型与value类型,以及其corresponding Writable实现。
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true)?0:1);
2. 实践案例:单词计数任务
2.1 准备工作
首先,我们需要准备一段文本作为输入文件。在这个简单的案例中,我们使用的是经典的小说《简·爱》中的部分内容:
The morning after my arrival I sent one of my servants to Bessie,
to ask her to bring me her little girl.
"Is she ill?" asked Bessie.
"No," replied I; "but I wish to see her."
Bessie looked surprised at this request; but she brought the child directly.
Her name was Adele Varens; she was a pretty little girl about seven years old,
with bright black eyes and hair.
I had never seen a foreigner before; but there was something in the child's appearance that reminded me of Helen Burns.
She seemed shy and reserved too.
I took a great liking to her immediately.
Adele spoke French fluently though with a slight accent;
and she told me that she had been born in Lyons.
Her father was dead—she said he had been killed in a duel some years ago—her mother lived still at Lyons,
and Adele hoped soon to join her there.
In the evening Mr. Brocklehurst called on me...
He is an elderly gentleman with rather severe features;
he has grey hair cut short,
a long thin nose,
and prominent eyebrows which meet over it...
His manner is grave and somewhat austere;
he looks like a man who would be very strict and severe if he chose—but perhaps he never does choose."
将这段文本保存到名为“input.txt”的文件中,然后运行我们的单词计数程序。
2.2 运行程序并查看结果
执行Java代码后,你会发现一个名为“output”目录下生成了一系列包含单词及其出现次数的小文件。这就是我们想要达到的目标——统计出所有出现过一次或多次的独特英文单词及其出现频率。
通过这种方式,不仅可以理解Hadoop MapReduce编程基础,还能看到它如何应用于实际的大数据处理任务之中。在大规模、高性能需求下的场景下,这种分布式计算模型无疑是不可或缺的一部分。



