江苏科技大学生成神器ChatGPT都懂你也来试试吗
我是京东科技的何雨航,和大家分享一下如何充分发挥ChatGPT的潜能。作为一个职场人,理解并应用这项新技术变得越来越重要,因为这种变革对于员工未必是好事情。比如IBM计划用AI替代7800个工作岗位,游戏公司使用MidJourney削减原画师人数等等。
要理解ChatGPT,首先要了解GPT模型的原理。ChatGPT是基于GPT模型的AI聊天产品,我简称它为GPT。
从技术角度看,GPT是一种大型语言模型(LLM),基于Transformer架构。实际上,GPT是“生成式预训练变换器”的缩写(Generative Pre-trained Transformer中文意为“生成式预训练变换器”)。
和传统AI模型相比,GPT模型的一个显著区别在于它是一种大模型。传统的AI模型通常是为特定的目标训练而设计的,因此只能处理特定问题。比如AlphaGO是一款很擅长下棋的AI模型。
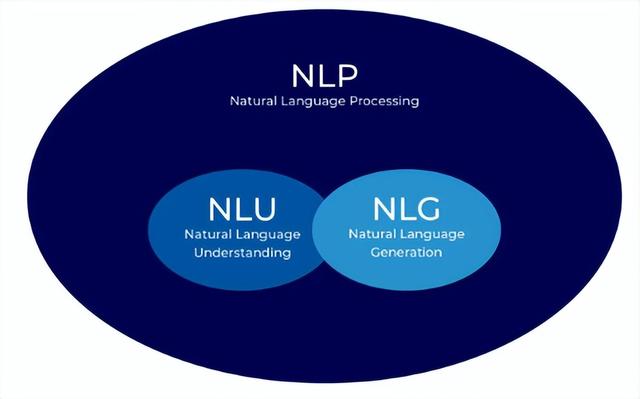
自然语言处理(NLP)试图解决更为通用的用户问题,不同于传统AI模型只能解决特定的问题。NLP主要包括两个关键步骤:自然语言理解(NLU)和自然语言生成(NLG)。
这里有两张图可以帮助解释这个过程:
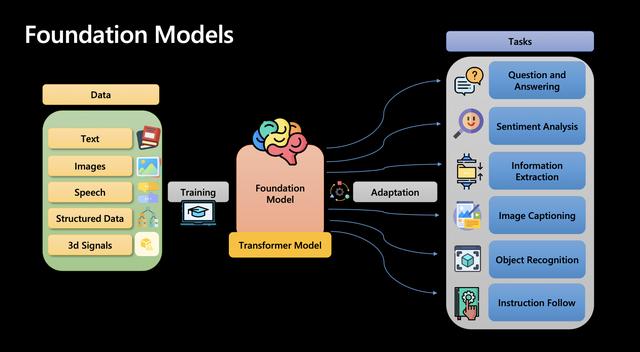
 而大型语言模型(例如GPT)采用了一种不同的策略,实现了自然语言生成层的统一。它通过将大量的知识融入到一个模型中,而不是针对每个特定任务分别训练模型,来实现解决多种类型问题的能力大大增强。
而大型语言模型(例如GPT)采用了一种不同的策略,实现了自然语言生成层的统一。它通过将大量的知识融入到一个模型中,而不是针对每个特定任务分别训练模型,来实现解决多种类型问题的能力大大增强。
这里有一张图,可以更好地解释这个过程:
 第一层:聊天能力。这是GPT最简单、最直观的用法,它的回答就是提供给客户的交付物。
第一层:聊天能力。这是GPT最简单、最直观的用法,它的回答就是提供给客户的交付物。
比如套壳聊天机器人:通过将一些基本的问题和答案匹配,机器人能够回答一些常见问题。
,我开发了一个套壳聊天机器人产品,它使用了OpenAI官方接口。这种产品的存在是因为它可以解决用户无法直接使用ChatGPT的问题,同时也存在竞争激烈的挑战。由于该产品的内容未经过滤,加上灰色性质,所以可能会被封锁,而且还可能需要频繁更换域名。 在第二层语言能力中,我使用了场景化问答的模式,对GPT的回复场景进行了约束。通过限定提示词、嵌入大量特定领域知识以及微调技术,使GPT能够仅基于某类身份回答特定类型的问题。对于其他类型的问题,机器人会告知用户不了解相关内容。这种用法可以有效约束用户输入内容,降低许多不必要的风险。 开发一个出色的场景化机器人需要投入大量的精力,但这种用法在智能客服、智能心理咨询和法律咨询等领域得到广泛应用。微软的new Bing是此类应用的杰出代表,其俏皮傲娇的回复风格深受网友的喜爱。限于聊天窗口的交互方式,我需要使用one-shot或few-shot的方法(在提示词中给ChatGPT一个或多个示例)来提升ChatGPT的表现。与用户的交互不再局限于聊天窗口,我预制了带有槽位的提示词模板,让用户只能输入限定的信息,对应提示词的空槽位。这种预制带槽位提示词模板的应用需要遵循一定的基本流程。 下面是一个图示,能更好地说明这个过程:
 另外,我还使用了AI辅助决策的方法,以第一个阶段为基础,将对应页面的部分功能与GPT联动。这样,在员工执行操作时,部分功能可以由AI实现,从而成倍提升效率。微软Copilot就是这种产品的代表之一。例如,在Excel中说明自己想要进行的数据分析,无需进行繁琐的手动操作,AI就可以快速完成相应的操作。下,我开始寻找相关公式,使数据分析可以自动进行。 另外,在AI的发展中,全自动AI工作流也是一个多么美好的愿景啊!虽然目前还处于演示层面,但AutoGPT、AgentGPT等产品已经为实现这一愿景奠定了基础。不过,要解决特定领域的细节问题,需要针对某个场景进行大量的微调与私有数据部署,这是GPT难以完成的。因此,目前全自动AI工作流还有很长一段路要走。 在国产大模型的发展方面,我始终认为AI技术是科学而非神学。如果训练数据质量达到标准,模型参数突破千亿便具备推理能力,突破八千亿可与GPT-4匹敌。我国采用了大量中文语料和中文微调,在不久的将来必将拥有符合本国文化背景、价值观的大模型。 然而,路漫漫其修远兮,困难也是极多的,例如训练成本极高、训练数据质量要求高、模型优化复杂、马太效应明显等。因此,预计在未来五年内,中国最多只会有3家知名大模型服务商。当然,大模型是AI时代的基础设施,大部分公司选择直接应用,以此来获取商业价值。率,对模型要求低
另外,我还使用了AI辅助决策的方法,以第一个阶段为基础,将对应页面的部分功能与GPT联动。这样,在员工执行操作时,部分功能可以由AI实现,从而成倍提升效率。微软Copilot就是这种产品的代表之一。例如,在Excel中说明自己想要进行的数据分析,无需进行繁琐的手动操作,AI就可以快速完成相应的操作。下,我开始寻找相关公式,使数据分析可以自动进行。 另外,在AI的发展中,全自动AI工作流也是一个多么美好的愿景啊!虽然目前还处于演示层面,但AutoGPT、AgentGPT等产品已经为实现这一愿景奠定了基础。不过,要解决特定领域的细节问题,需要针对某个场景进行大量的微调与私有数据部署,这是GPT难以完成的。因此,目前全自动AI工作流还有很长一段路要走。 在国产大模型的发展方面,我始终认为AI技术是科学而非神学。如果训练数据质量达到标准,模型参数突破千亿便具备推理能力,突破八千亿可与GPT-4匹敌。我国采用了大量中文语料和中文微调,在不久的将来必将拥有符合本国文化背景、价值观的大模型。 然而,路漫漫其修远兮,困难也是极多的,例如训练成本极高、训练数据质量要求高、模型优化复杂、马太效应明显等。因此,预计在未来五年内,中国最多只会有3家知名大模型服务商。当然,大模型是AI时代的基础设施,大部分公司选择直接应用,以此来获取商业价值。率,对模型要求低
依赖对抗学习
普适性强,但对模型要求较高
微调模型
最高效,但同时往往收益也是不确定的。
3.针对性模型设计GPT的应用需要针对具体场景进行设计,只有将GPT应用于客户真实的问题时,才能取得最佳效果。第一步是构建语料库。在实际应用时,我采用的方法是使用一些已有的语料库,当然还有部分需要自己搜集。语料库收集到的数据需要有严格的清洗和标注,确保数据的准确性和真实性。然后就可以进行模型的构建,模型的调优也是高精度实现的关键。
最后,我深知在AI技术领域彼此分享是最珍贵的。如果您对本文内容有任何建议,欢迎联系我,感谢大家的阅读和支持!
我对GPT技术的应用的几种方法进行的总结。首先,我发现使用提示词优化可以大大提升GPT回复的效率,而成本却非常低。但是需要注意的是,过多的提示词可能会影响上下文关联的长度,因为这会占用很多的token。另外,通过扩展GPT的知识库,可以降低调优的成本。虽然GPT并不真正理解相关的内容,但在遇到相关问题时,它能基于给定的知识库回答。
而微调技术则是搭建真正的私有模型,让GPT能够理解相关问题。虽然成本较高,需要大量的“问答对”,训练过程也非常消耗token,但效果会更好。
针对具体场景进行设计时,我总结了三种调优方法,包括提示词优化、embedding和微调模型。其中,提示词优化是最重要的方法,它可以通过探索找到最优提示词模板,预留特定槽位以供用户输入。好的提示词应包含角色、背景、GPT需执行的任务、输出标准等。据研究表明,好的提示词可以使GPT3.5的结果可用性由30%飙升至80%以上。
我总结了GPT技术在应用中常用的三种方法。第一种是使用提示词优化,这可以大幅提升GPT回复的效率,但需要注意过多的提示词可能会影响上下文关联的长度。第二种方法是将自有知识库使用embedding技术向量化,这样GPT就能基于自有数据进行问答。第三种方法是通过输入大量问答,让GPT真正学会如何回答某类问题,这个方法是成本最高的,但能够将提示词的短期记忆转化为私有模型的长期记忆,从而释放宝贵的token,以完善提示词的其他细节。这三种方法并不冲突,在实际的工程实践中往往会互相配合,特别是前两种。
在构建私有模型时,私有数据集非常重要。私有数据集可以用于训练模型,解决特定领域问题。我建议使用微软Azure提供的GPT接口,搭建带有私有数据的大语言模型产品。因为微软面向B端的GPT服务为独立部署,不会将私有数据用于大模型训练,这样可以有效保护私有数据。私有数据一旦公开,价值将大打折扣。通过以上几项能力的加持,大语言模型可以充分释放在解决依赖电脑的各种问题方面的巨大潜力。我总结了下一个时代(3年内)的业务运营模式,如下所示:
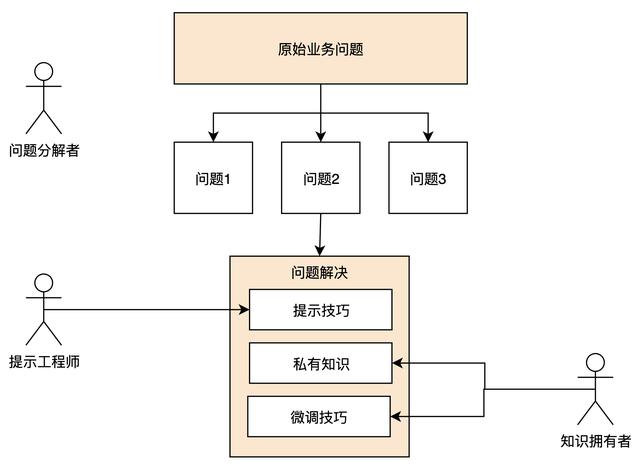 企业会根据三大能力衍生出三大类角色,我将它们介绍如下:
企业会根据三大能力衍生出三大类角色,我将它们介绍如下:
第一类是问题分解者,我负责将业务问题有效地分解成GPT能够处理的子问题,并将这些子问题拼接成更完整的答案。
第二类是提示工程师,我能够有效地与GPT进行沟通,根据不同的问题类型给出有用的提示词模板,从而大大提升GPT的输出质量。
第三类是知识拥有者,我拥有丰富的行业knowhow,并且能够将这些知识结构化,传授给GPT,这类角色就像现在的领域专家一样。
有了这种模式的推动,GPT将成为企业提效的重要帮手,我们可以解决大量重复性劳动,节约人力成本。我认为,AI技术虽然可以提供有价值的参考,但人的主观能动性仍起着决定性的作用。
即使以GPT-4为代表的AI技术保持当前水平,带来的效率提升已经令人震惊,更不用说其仍能以飞快的速度进化。从技术的发展史来看,一项大幅度提效的新技术出现,往往先惠及B端,然后才慢慢在C端开始释放巨大的价值。而这是由企业对效率天然的敏感性所决定的,而改变C用户的习惯则需要大量学习成本与场景挖掘,滞后效应相对较强。举三个例子来说明:
第一个例子是回顾第一次工业,内燃机的出现导致了纺织女工大量失业,而后才逐渐找到了各种C端场景,推动了社会生产力的大幅度提升。
第二个例子是有ChatGPT这样的技术,可以更快地生成口水文章,但是C端用户对阅读的诉求并没有增加。对于营销号公司来说,虽然效率提升了,但也意味着他们所需要的人将变少。
第三个例子是MidJourney,其可以快速生成抱枕图案,但是C端用户并不会因此购买更多的抱枕,因此需要制图的人员就需要重新考虑如何提升产品价值。
因此,AI技术可以说是B端与C端效率提升的关键,但在B端的发展可能比在C端更加快速。对于C端用户而言,他们更加关注的是产品的使用体验与感受,而这些需要我们将AI技术与人类智慧相结合,才能够真正满足他们的需求。我认为,信息化企业的内效正在到来,电脑上的重复劳动将会消失,因为大模型最擅长学习这些事情。正如我之前所举的例子,像IBM公司缩减7800个编制的案例,这样的情况只会越来越频繁。
AI时代真的已经到来了,每个岗位都需要思考如何让AI成为工作上的伙伴。
相关文章