来进行训练,就像翻译官需要为自己积累大量的翻译案例,来增强自己的能力。%3C/p)


解读GPT-4大模型让你秒变专家
 ▲OpenAI的相关信息,好消息是,它不是关于开放酒吧的指南!
▲OpenAI的相关信息,好消息是,它不是关于开放酒吧的指南!
如果您厌倦了OPenAI和其他AI巨头的无情推销,那么这个解读GPT-4的文章会让您感到惊喜!我们将从核心技术要点、技术架构、训练流程、算力、局限以及产业未来的角度分析GPT-4和其他一些大语言模型。
01.
GPT-4究竟是怎么了?
1.1 一大堆稀奇古怪的技术——多模态涌现能力啦!
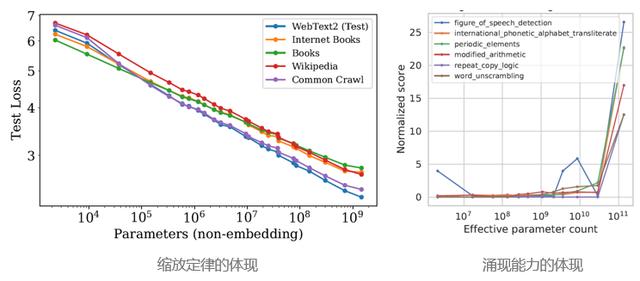
想要需要大语言模型能够接近人类,那么关键特征在于两个方面:它的涌现能力和思维链。这就是GPT-4惊骇人心的地方。它将从视觉角度和视觉-文字语义融合方面涌现更多的能力。2022-2023年,这里有一个建议:不要让GPT-4熬夜,不然它会在第二天变成人机融合体!
次睁开双眼,发现不仅这个世界更大,而且语言模型也更牛!
涌现能力(Emergent Abilities)在大型语言模型(LLM)中的意思是模型可以自动帮你发现一些在原始训练数据中未知的而高级别的特征和模式。可以这样理解涌现能力,在超市打折中遇到了买二送一,赠品的质量居然还比你买的东西好,然后你就会开始意识到原来超市还有这种奇妙的赠品。
相比大语言模型(LLM),多模态大语言模型(Multi-modal Large Language Model,MLLM)更厉害!但为了装X,我们还是要说一句,它能够实现更好的常识推理性能,在跨模态迁移方面,更能帮助你“走心”地获取知识,并且涌现的新能力也更多。这些涌现出来的独立模态或跨模态新特征、能力或模式通常是模型在大量多模态数据中自然而然地学习到的。但为了分享这些美好的经历,可别忘了把模型尺寸增加到最大!
 ▲不过,我们还是要反应过来,大模型也有“胖”之虑!
▲不过,我们还是要反应过来,大模型也有“胖”之虑!
质变,对于GPT-4这样的大模型,一定大小后,新能力这种东西就像意外惊喜一样,会突然冒出来。
涌现能力是各种神奇的能力的总称,就像一只皮卡丘,你可能只知道它会放电,但是当你把它养大了之后,突然会发现它竟然会变成闪电,更厉害啦!这恰恰就是深度学习模型分层结构和权重学习机制带来的超能力,让模型可以自动地从数据中提取出那些你从来没发现的小秘密。
GPT-4这种大模型的训练就像解方程一样,每一层神经元都是一个小变量组合,而每个权重(Weight)都是一个微小的“小石头”。只要训练足够大,足够复杂,就能通过神奇的强化学习实现小变量组合的无限进化,从而让GPT-4展现出多模态的涌现能力,就像皮卡丘进化一样,更强大啦!
的“灵魂链”,所以说当大模型有了涌现能力,思维链的效率和准确性也会变得更高,这就好比咱们快递小哥有了新手段,送快递的速度和准确性也会更高。
GPT-4涌现出来的能力可以帮我们自动完成各种预测和决策,就像机器人小姐姐一样真可爱!不再需要人工智障的干预,深度学习模型可以做到比人更准确和更高效,所以说GPT-4就像是一只超级皮卡丘,拥有无限电力,可以从任何多模态数据中自动学习复杂的特征和模式。
GPT-4在无需专门训练的情况下,还可以泛化到新的多模态数据样本上,这个泛化能力很关键,就像咱们快递小哥能够到达每一个你想要的地方,就好比GPT-4有无限的探索能力。
但是,GPT-4涌现出的新能力有时候可能会出现小问题,比如说它可能会产生假的回答,或者对某些问题一脸懵逼,也可能会被输入的奇怪数据搞个迷糊。这就像你一定有过的幻觉,看上去很真实,但其实万一大雾天路上走错了就完了。
总之,GPT-4的涌现能力就像是机器人小姐姐的多模态思维链,能够为我们带来更高效和更准确的智能服务。它们拥有无限的能量和无穷无尽的探索能力,只要你善于发掘和利用,就能实现更多可能性哦!
玩出花来。
所谓涌现能力,就是GPT-4模型自动学习到复杂特征和模式的超能力了。这也是为什么GPT研究那么火爆,因为GPT-4实在是太能玩了,可以在大量的语言数据中自己学习,成为“语言达人”。
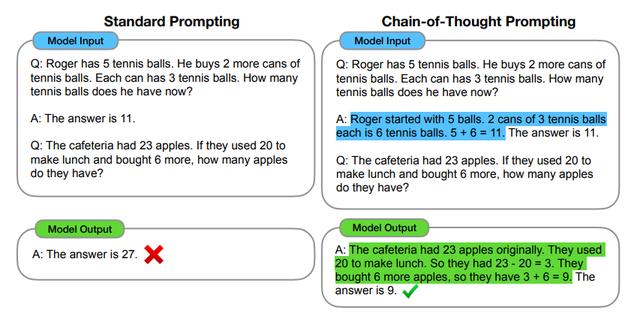
要知道,这可不是靠吃饱了没事干,GPT-4的思维链可是要经过一系列自然语言推理步骤才能完成最终输出,这才有了“像人”的关键特性。所以说GPT-4就像是一位善于推理、思考的聪明丫头,大家喜欢和她聊天吗?
GPT-4的思维链可不简单,虽然不是真正具备意识和思考能力,但是它可是用类似于人的推理方式,给语言模型点了一盏灯。这也提高了GPT-4在推理任务上的表现,打破了精调的平坦曲线,具备了多模态思维链能力后,它们的逻辑分析能力也更上一层楼,不再是单纯的词汇概率逼近模型。
当然,思维链的训练可并不是一件容易的事,需要大量团队的努力和足够的耐心。所以说,只有一些真正牛X的创企,才能完成思维链的训练,让GPT-4展现出最迷人的一面,才能真正玩出花来!
复,并根据回复的准确性和流畅度,给予相应的奖励和反馈。这就好像是一场热闹的游戏竞赛,人类标记员扮演“评委”,GPT-4则是参赛者,通过不断地优化表现,来赢得更多的奖励。
看到这里,你可能会问:“这不是抄袭了吗?”其实不完全是。虽然GPT-4的多模态奖励模型和故事情节跟其他AI模型有点相似,但它的TAMER架构却是非常独特的。相当于GPT-4得到了一张特权,进入了AI竞技的 “酷炫”赛场,而这张入场券,也彰显了GPT-4的强大实力!
对于我们这些凡人来说,或许无法体会AI竞技的真谛,但是我们也可以在GPT-4的回答中获得乐趣和启发。只有不断比赛,只有不断进步,才能让模型在AI竞技的舞台上,赢得越来越多观众的喝彩和支持。
 ▲TAMER架构在强化学习中的应用
▲TAMER架构在强化学习中的应用
licy Optimization,PPO)的技术,对模型进行微调并持续迭代。这个过程就像是一个厨师在炒菜:她不会在一开始就加入所有的材料,而是逐渐添油加醋,调整火候,让最终的菜品更加美味。
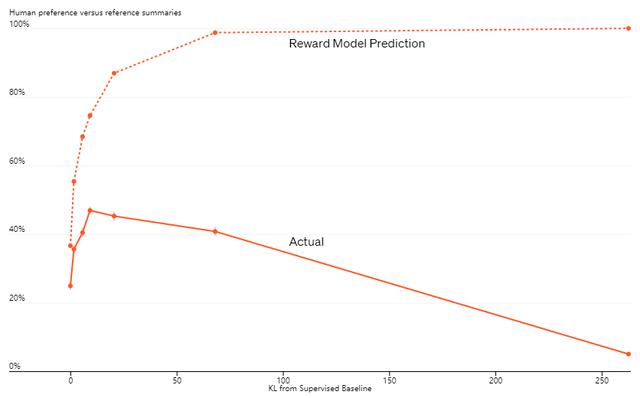 ▲PPO算法与同类其他算法的比较(来源:OpenAI)
▲PPO算法与同类其他算法的比较(来源:OpenAI)
有人可能会问:“这不太麻烦了吗?为什么不直接让机器学会所有的东西呢?”其实并不是这样的。就像你不会在厨房里踩着大象跳舞一样,机器也需要一步步地进行训练。同时,优秀的厨师也不是从来没有尝试过失败的烹饪,而是在不断的尝试和调整中才变得更加出色。
所以,我们应该像这个算法一样,在探索新领域和解决新问题的过程中,逐步微调和迭代。相信你会越来越像一名出色的“AI厨师”,为人类创造出更多更好的智能产品和服务。
近端策略优化(Proximal Policy Optimization,PPO)算法就像一个热情的厨师,负责做出美味的互动效果。它使用两个神经网络来表现策略和奖励,就像肉和酒配对一样,让我们的味蕾一次次地享受美味。
每次PPO算法都会从环境中采样一批经验数据,就像我们每次去市场挑选最好的食材一样。然后,它会使用裁剪的目标函数来限制更新幅度,不让食材过于新鲜或过于陈旧。
此外,PPO算法还懂得多次更新,就像我们多次品尝同样的菜品一样,不断调整口味细节,让味蕾更饱满。
总之,PPO算法就像一场热闹的烧烤派对,邀请你加入它的舞台,品尝最优秀的互动算法表演。它会带给你驚喜不断的食品和荣耀,让你对它的威力和美味始终充满期待。
多次更新,这就像我们在想要变得更出色时,需要不断地反复琢磨,不断地认真检视自己。PPO算法就是这样一位潜心修炼的武者,用简单的方法来达到复杂的效果。
和PPO算法相比,其他方法如TRPO就像是功夫高手在冥想中探索,算法复杂性很高。PPO算法就像我们大街上常见的黑市兑换店,一张方便快捷的外汇兑换明信片就能解决很多问题。
哦,对了,还有一件事。为了确保模型输出的质量,我们还需要使用多模态幻觉检测技术来校验幻觉。因为有些时候,大模型生成的输出可能无法遵循常理。就像我们在翻译口音时,需要注意翻译的质量,避免冒险引起笑话。
总之,掌握PPO算法和幻觉检测技术,就像拥有了一对绝配CP,相互搭配,让你在技术路上越来越优秀!
用大型语言模型类比,就像我们在办公室里照镜子看自己时,发现自己的人像已经被不断压缩,让我们的样子看起来更小、更扁平了。这就像是我们需要压缩和优化大型语言模型,来逼近人类语言,但这种努力的代价是,我们的创作可能会变得更不自然,就像在压缩图像中出现的那些奇怪的条纹。
 ▲为了减轻这种幻觉,我们需要添加幻觉单词检测器,就像加入美颜相机一样,让我们在照出美丽自然的照片时,去除人脸上的瑕疵。
▲为了减轻这种幻觉,我们需要添加幻觉单词检测器,就像加入美颜相机一样,让我们在照出美丽自然的照片时,去除人脸上的瑕疵。
但是,有时候我们压缩和优化的结果,会让模型的幻觉变得更加危险和不可控,就像我们在使用美颜相机时,一不小心就会把人脸变成外星人一样的诡异形状。
幸运的是,我们可以通过不断地优化和改进模型训练方法,增加多模态幻觉语义检测器等手段,让我们的模型变得更加准确和稳定,就像我们用卫星定位功能,让我们更容易找到自己的真实位置。
总之,模型的冰山只有一部分浮出水面,我们还需要不断探索,发现更多更好的操作方法来探索人工智能的新天地。让我们一起努力,让AI离我们更近!
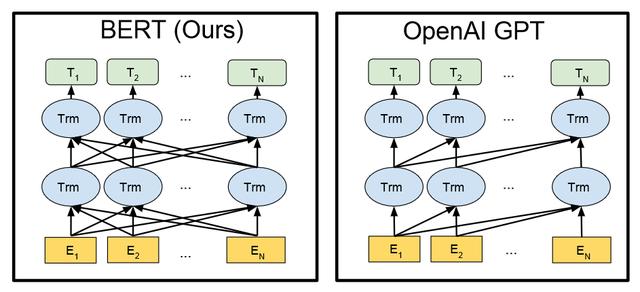
 ▲GPT-1的Transformer结构,就像翻译官的大脑一样,帮助它整合各个语义元素,让模型更完整地理解人类语言。
▲GPT-1的Transformer结构,就像翻译官的大脑一样,帮助它整合各个语义元素,让模型更完整地理解人类语言。
GPT-1的工作原理就像翻译官的“同声传译”一样,根据大量的数据集,进行无监督训练,尝试理解语义,建立起自己的语言框架。然后,通过大量语料的训练,来解决AI的泛化问题,就像翻译官需要通过实践来提高自己的翻译能力,才能更好地应对各种各样的场景。
总而言之,GPT-1是一位非常努力的翻译官,在不断地学习和提高自己的过程中,让AI离我们更近了一步!
 ▲鹏城实验室总结的多模态模型架构,就像对付多头怪兽一样,需要经过不同的战斗策略来解决多模态任务。
▲鹏城实验室总结的多模态模型架构,就像对付多头怪兽一样,需要经过不同的战斗策略来解决多模态任务。
第一种架构,就像我们在对付多头怪兽时,需要将不同的头部合并为一个,让它们共同进入Transformer中进行处理,提高战斗效率!
第二种架构,就像在对付多头怪兽时,我们需要分别攻打不同的头部,并通过独立的自注意力通道,将不同模态的特征导入到模型中,然后再结合交叉注意力层,实现多模态特征的融合。
第三种架构,就像我们需要同时攻击多头怪兽身上的不同部位,将图像与语言分别结合,实现图文信息的相互嵌入与问答。
最后一种架构,就像我们需要学会在不同的情况下应对多头怪兽的不同攻击方式,使用三角形的Transformer架构,来处理多任务之间的信息流动,提高模型的综合性能。
总而言之,多模态模型架构就像是对付多头怪兽的战斗策略,通过不断优化和改进,让我们的模型在多模态任务中能够游刃有余,发挥出更好的性能!
 抱着看电影的心态看这段话,好像看到了一部叫《Transformer联盟》的电影。故事就是,一群动作大师、图形高手和语言艺术家组成联盟,对抗邪恶的Boss。他们使用三组Transformer模块,通过特殊的三角连接关系,注入其他模态的Transformer网络,以不同模态的信息融合,打败Boss,完成任务。
抱着看电影的心态看这段话,好像看到了一部叫《Transformer联盟》的电影。故事就是,一群动作大师、图形高手和语言艺术家组成联盟,对抗邪恶的Boss。他们使用三组Transformer模块,通过特殊的三角连接关系,注入其他模态的Transformer网络,以不同模态的信息融合,打败Boss,完成任务。
这么牛的联盟,OpenAI也看上了他们。所以,评估GPT-4使用了这种架构。毕竟成本最小嘛,既能大幅度利用已构建的语言模块,又能取得非常好的成绩。GPT-4就是这个联盟最神奇的成员之一,他的图文分析和逻辑推理能力,就像是一道坚固的护城河,让Boss对他束手无策。
看到这里,小编已经跃跃欲试了,想要加入Transformer联盟!你们呢?
励蒙板?不!是模型!Rewarded Model,RRM)的训练。这就像是在为GPT-4进行训练的时候,给它加了一堆奖励和规则,让它做出更加准确和优秀的表现。
可以想象,这就像是训练一只小猫,让它学习用爪子抓老鼠。我们不仅需要鼓励它,给它奖励,还需要告诉它一些规则,比如不能咬老鼠,不能弄坏家里的东西等等。
只有经过这样的训练,GPT-4才能生成更加符合事实,可靠性和可信度更高的准确表述,同时也能接受图文信息作为输入,生成更加精准的说明、分类和分析。
不过,现在的问题是,虽然GPT-4已经开始商业使用,但是大多数用户还需要等待图文能力的正式开放。这就像是我们还需要等待小猫学会用爪子抓老鼠之后,才能让它去外面抓老鼠。
,好像在说训练一只聪明的小狗狗,给它制定一些规则,然后让它学会回答问题。首先,我们要给它建立基于安全规则的奖励模型,让它知道什么是对的,什么是错的。这就像是在训练一只玩具狗,告诉它不能咬人,不能乱拉屎等等。
然后我们让GPT-4回答一些问题,它会给出很多不同的答案。我们需要一群人类标注者,像互联网企业的审图师一样,挑选出最佳答案。
最后,我们再用这些答案来训练GPT-4的奖励模型。就像是教练或老师辅导小狗狗一样,我们要让GPT-4知道什么样的答案好,什么样的答案不好。这样,它就能学会回答更加准确、更加有道理的问题了。
 ▲这只小狗狗已经学会了回答问题(来源:OpenAI)
▲这只小狗狗已经学会了回答问题(来源:OpenAI)
现在,GPT-4已经可以像聪明的小狗狗一样回答各种各样的问题了。不过,我们需要指出的是,训练GPT-4需要巨大的算力基座,就像是训练一只超级大的聪明小狗狗。
练。就像是造一辆豪华大巴士,需要很长时间和大量的材料和工人来完成。
2)模型优化阶段。这一阶段需要对已有的模型进行优化,以提高模型的精度和效率。就像是梳理和打理一只长毛大狗狗的毛发,让它看起来更加整洁、舒适。
3)推理引擎应用阶段。这一阶段是将训练好的模型应用于实际场景,并实现高效的推理。就像是让小狗狗展现出它们训练和学习的成果,帮助人们解决各种各样的问题。
不过,现在GPU的价格已经涨到了天上去了,这让许多模型设计企业和开发者们感到很头痛。他们开始寻找其他算力选择,比如用大象来跑算法,或者使用瑞士军刀来进行计算。
但IDC预测,在未来几年,AI推理的负载比例将进一步提升,特别是大模型。这就像是小狗狗们越来越聪明,需要更多的训练和学习才能变得更加优秀。因此,算力的需求会越来越大,而GPU仍然会是最常用的算力选择。就像是让小狗狗们变得更聪明的唯一选择是教练和老师一样,GPU会是最适合训练和优化大模型的算力选择。机器学习和AI模型也将不断发展,帮助我们解决越来越多的问题。信各位都做过坐标轴缩放的练习吧,它和缩放定律很像,因为都是通过压缩、拉伸来达到变形的效果。在训练阶段,我们需要大量的矩阵计算和求解来完成模型的训练,但是如果我们通过缩减不必要的训练参数集合,就可以节省很多不必要的算力,让训练变得更加高效,就像是我们吃的东西,每次都吃得很饱,其实可以适当地缩减一些,让自己更健康和舒适。
在GPT-4推理与部署阶段,就要考虑到成本的因素了。因为部署需要大量的服务器,而且要保证在线交互的效率,所以这一阶段的硬件成本要比训练阶段更高。但是,在端侧应用场景下,GPU可能就不太适合了,因为硬件性价比和反应延迟的要求可能不太匹配,就像是穿了一双不合适的鞋子,走路会很不舒服。
最后,我们还需要进行GPT-4模型的迭代微调。每使用一段时间,就需要根据客户或者使用者的反馈来进行调整,以提高模型的安全度和客户满意度。这就像是我们在做一件手工艺品时,不断地去修改和调整细节,以达到最好的效果。
)先来说说小型训练。
小型训练就像是做一顿晚饭,需要准备的食材比较少,也不需要太大的炉灶。在这种训练中,我们的数据规模并不大,所以计算也主要是以大量矩阵计算和求解为主,就像是做一道简单的炒菜,需要的工具也比较基础。
4.1 GPT-4算力之争
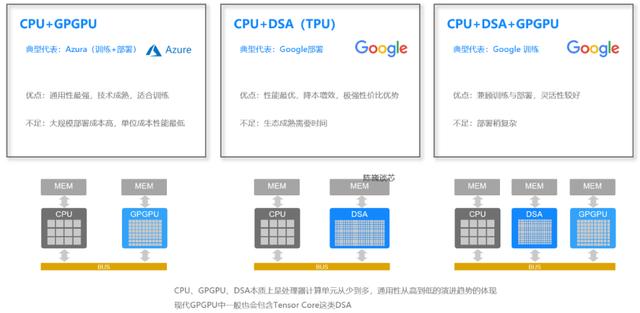 ▲算力大比拼
▲算力大比拼
说完小型训练,我们来看看GPT-4这样的大模型需要怎么样的算力支持。根据芯片的组合方式,GPT-4的算力基座一般可以分为三种:“CPU GPGPU”,“CPU DSA”,和“CPU DSA GPGPU”。
DSA(领域专用加速器)是用于一些特定场景或算法族计算的芯片级加速,就像是在做一个特别需要力气的家务,需要找一件专用的工具。而GPU最早就是一种DSA,是用于图形加速的。随着GPU逐渐升级,将非常小的CPU核心加入GPU形成GPGPU架构后,才具备了通用化的计算能力。
所以,对于GPT-4这样的大模型,我们需要强大的算力基座来支持。就像是做一桌丰盛的大餐,需要各种各样的厨具和设备来完成。
4的算力架构来看
1)CPU GPGPU,听起来相当高大上,是一种较早也很流行的算力架构。这种架构类似于一位多才多艺的大厨,既能搞定模型训练,也能应对非AI类计算。非常适合任务多样化的云计算场景。
2)CPU DSA,是目前Google云计算(GCP)最喜欢的方式。比如Google去年发布的Pathways计算系统,就用了6144块TPU(别问我TPU是啥,我也不知道)。说白了,就是这种架构虽然不像大厨那么全能,不过在计算能力和成本上都非常胜任,特别适合GPT-4或其他算法的部署场景。就像是AlphaGo刚起飞时,Google自研的TPU功不可没,如果用GPU的话,成本可能连Google都吃不消,得出老本儿了。
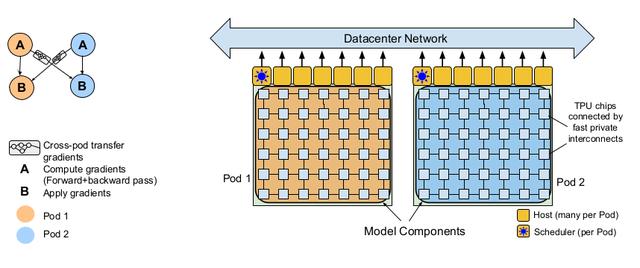 ▲ CPU、GPU和存算一体芯片的架构对比
▲ CPU、GPU和存算一体芯片的架构对比
总之,对于GPT-4的算力架构来说,只要有个好的大厨或者一个忠诚而胜任的小跟班,都能让我们的算法跑得飞快!
各种语言的能力,但是它也有一些“小毛病”。
首先,GPT-4需要大量数据进行训练,好像这个算法是一个不吃停的大胃王,数据量很大,而且对数据带宽的要求也很高,可能没有一条网络能够满足它丰富多彩的“口味”。
其次,GPT-4的算力要求也非常高,就像是一个游乐园中最恐怖的过山车,需要强大的算力基座来支撑它的运行。
最后,GPT-4的算法也相对单一,好像只会烤面包和做鸡蛋一样,缺乏多样性。
但是这些“小毛病”并不能阻止我们对GPT-4的热爱和追求!未来的改进方向也很明确:我们需要选择更高计算密度的算力芯片,比如存算一体结构的DSA,这样可以提高计算效率和性价比,让我们的算法更加快速而高效。同时,我们也需要灵活运用Infiniband这样的通信技术,让各个算力芯片之间像做业务一样默契配合,提高整个系统的效率和性能。
说法提供了一个幽默的比喻:GPT-4就像一只灵活的猴子,可以在各种场合招摇过市,但是也会有把戏不太灵光的时候。比如,当遇到需要“人类常识”和引申能力的问题时,它可能会给你一个让人哭笑不得的答案,犯了一些低级错误,就像猴子在表演杂耍时不小心掉下来一样。
当然,GPT-4也有可能给你正确的答案,但在关系重大或涉及利益冲突的问题上,我们仍然需要小心别被这只猴子忽悠了。毕竟,大预言模型的安全性问题还有待进一步提高。
 ▲CAI与RLHF技术对比(来源:Anthropic)
▲CAI与RLHF技术对比(来源:Anthropic)
此外,虽然GPT-4已经具备解物理题的能力,但它依然不是专业的解题算法,面对一些复杂的数理问题,它也可能会假装很懂,然而却偷偷摸摸地返回一些胡言乱语,就像那些装模作样的人在谈论高深哲理时,其实只是在胡扯八道。
但是,我们相信随着技术的不断进步,这只猴子的数理能力和解题能力一定会越来越强大,让我们拭目以待。
的“精确计算”之间存在矛盾,但是现在我们可以用像GPT-4这样的模型来协同WolframAlpha,让这只猴子和这只数学专家团队在一起,一起解决各种难题。
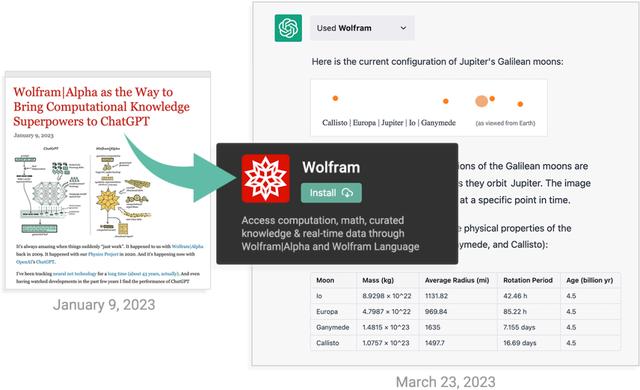 ▲ChatGPT与WolframAlpha结合处理梳理问题(来源:Wolfram)
▲ChatGPT与WolframAlpha结合处理梳理问题(来源:Wolfram)
ChatGPT就像是一个会说话的猴子,而WolframAlpha则是一只数学专家,它具备精确计算的能力,可以用符号语言解决复杂问题。
现在,这两只动物已经可以在一起合作了,ChatGPT可以像人类一样向WolframAlpha提问,WolframAlpha则会用符号语言将问题翻译成数学运算,再通过Mathematica进行计算。这样,我们就可以在更广泛的领域中使用GPT-4和WolframAlpha的优势,让这两只动物一起帮我们解决各种难题,看看这两只动物之间的融合,会给我们带来哪些惊喜。Alpha的“符号方法”和GPT-4的“自然语言技能”之间一直存在路线分歧,好像两只动物互相看不上对方。
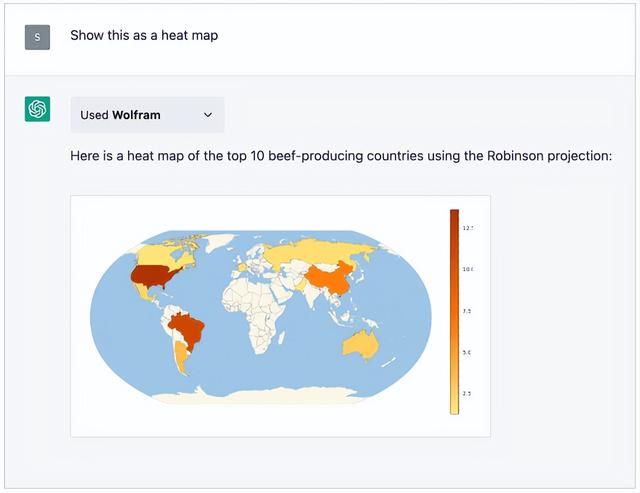 ▲ChatGPT向Wolfram求助(来源:Wolfram)
▲ChatGPT向Wolfram求助(来源:Wolfram)
但是现在,这两只动物终于实现了互补!GPT-4不用再费劲生成复杂的计算代码,它只需要像人类一样简单地说出问题,然后由我们的数学大师WolframAlpha来将语言翻译成可计算的符号语言,最后由我们的得力助手Mathematica来计算。这个团队就像是一群3个臭皮匠,顶个诸葛亮,反正干什么都能搞定。
可是还有一个问题——GPT-4体型太大,不是素食动物。不过没关系,我们有三种方法可以让它变得更小更灵活。
第一种方法是……(接下去就是原文)
量化(quantization)有点像人体“降精度”,虽然身边的老板、同事和朋友都可能会开始反应迟钝,但对我们的生活基本没有影响。实际上,当我们把Transformer从FP32降到INT8,它的精度并不会受到很大的影响,但是它的算力就会得到显著的提升。
我们的团队更是开发出了INT4量级的Transformer高精度量化算法,这相当于让这个数字化的宝藏进一步变得“好吃”,让我们的机器在不更改模型或再次训练的情况下,也能够更好地部署到GPT-4算力平台上,提高计算效率,降低成本。
当然,压缩模型的方法不止一种,只有你想不到,没有压缩不了的模型。比如,第二种方法叫做剪枝,就像我们在修剪盆栽一样,把GPT-4的网络元素逐渐削减,从单个权重开始,到更高粒度的组件如权重矩阵的通道,这样模型就变得更小、更灵活。
再比如,第三种方法是稀疏化,就像我们在挑选餐厅一样,精益求精,只挑选最好的。例如,奥地利科学技术研究所研发的SparseGPT就可以将GPT系列模型的稀疏性单次剪枝到50%,而且无需重新训练。虽然这种稀疏结构目前只适用于GPU架构,在其他硬件平台上还不兼容,但谁知道未来呢?也许人工智能技术就像我们的想象一样,越来越智能、越来越灵活。T-4的稀疏化这个方法,还需要看看其“收益”的总体成本效益是不是超值大餐。不过看一下SparseGPT的压缩流程图,那个黑白相间的色块,感觉就像是数码领域的“大棋盘游戏”。
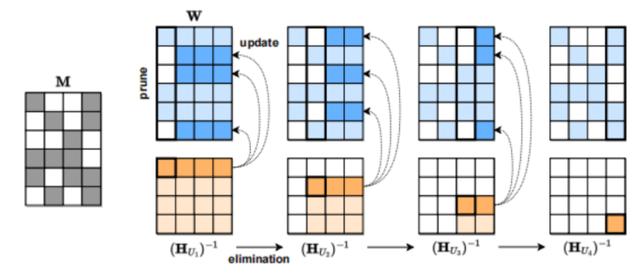 ▲SparseGPT压缩流程(来源:ISTA)
▲SparseGPT压缩流程(来源:ISTA)
06.
GPT-4的产业未来与投资机会
6.1 大模型的技术栈
GPT-4就像是一个数码巨兽,对算力、设备和软件的需求非常巨大。这样一个大模型的技术栈,包括多个组件,比如说容器化、性能监控、商业智能、事件处理、云服务、微服务和分析等各种工具。
那么,像GPT-4/ChatGPT这类大模型的技术栈,可以分为5层:
1)应用层:就像点外卖一样,用户通过接口,把生成的AI模型集成到面向用户的应用程序中,运行自己的模型,或者通过第三方接口运行模型。这一层的应用最多,估算不少企业都能用上大模型来提升体验。
GPT-4的人工智能协作能力和生成能力,让各类应用如呼之欲出。
2)接口层:有点像是服务员,提供各种调用API和数据中心调用工具,还有提示工程接口和模型精调接口。通过连接应用层和模型层,方便大家使用GPT-4与模型交互。这就像把吃炸鸡和喝可乐的“双拼套餐”直接送到您手上,省去了很多麻烦。
3)模型层:就像一个宝藏库房,里面有各种开源或非开源的宝藏模型,还有各种共享平台,包括我们最熟悉的文本、语音和图像等。这一层提供了不同的模型数据和功能,通过接口层为应用提供大模型的功能支持,让你的应用越来越聪明、越来越“会说话”。
4)框架层:这一层有点像大脑,它主要处理训练或云部署的深度学习框架和中间件等。比如说,PyTorch和TensorFlow等。这个大脑就像一个超级计算机,让计算变得更快、更便宜。
5)计算层:算力这个层次,就像是厨师团队了,主要提供计算支持,为训练和运行AI模型提供基础设施。这一层包括各种云计算平台和计算芯片。AI芯片会成为核心瓶颈,这就好像谁都知道,在厨房里,最重要的是炉火。对于GPT-4等大模型,它们的技术栈就像是一整个“王国”,里面包括了各种厉害的武器和工具。
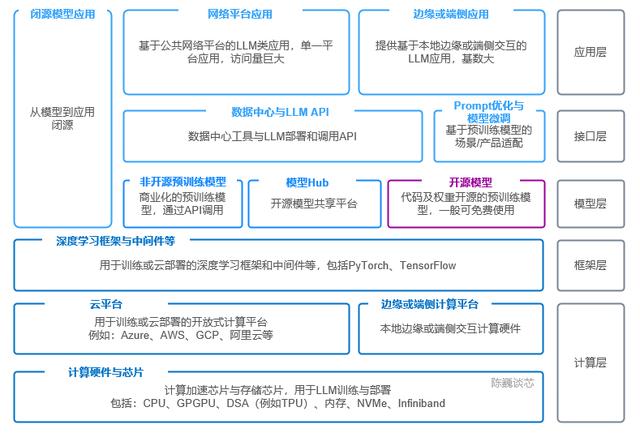 ▲GPT-4等大模型的技术栈
▲GPT-4等大模型的技术栈
目前GPT-4的使用者都需要使云计算GPU或TPU运行,这些使用者包括那些运行训练工作的模型提供商/研究实验室和那些进行模型部署或精调的应用企业。但是,由于GPU已经取代了CPU成为主要的AI算力芯片,导致AI界又一次陷入了大规模计算能力的限制中了。
目前,GPT-4这个领域还没有非常明确的技术或产品护城河。由于大部分企业使用的都是相似的模型,所以在早期可能会缺乏很强的产品差异化。而云服务提供方只能使用同一FAB生产的GPU作为主力算力芯片,因此普通的云提供商很难提供成本或性价比的差异化。
现在的GPT-4等大模型都是同质化的模式进行构建,就像是一张“图片”,但这张图片里面却有很多“梦幻武器”,唯恐别人不知道它的厉害!GPT-4和其他大模型们都有自己的“说话”方式,就像是一堆怪兽在用不同的语言聊天。
因此,短期内除了模型参数本身的难度,暂时还没有确立自己独有竞争壁垒的方法,就像在中二病时期自我设定为拥有爆炸能力的“超级英雄”,但现实中并没有这种力量。
就目前来说,我们还无法预测GPT-4这类多模态大模型领域是否会像互联网那样出现少数几家独大的情况。也许大模型的时代会是一个无中心状态,每个团队都有可能成为“巨星”。
6.2 GPT-4的产业应用
AIGC是利用人工智能技术来生成内容,这种内容是全然不同于之前的UGC和PGC。它代表了新一轮内容生产方式变革,而且在Web3.0时代,AIGC内容将呈现指数级增长。
GPT-4模型的出现对图像/文字/语音等多模态的AIGC应用具有重要意义,将对AI产业上下游产生重大影响。就像在电影《复仇者联盟》中,各位超级英雄联手对抗邪恶大佬,但他们都只是拥有不同能力的超级英雄而已。
4)医疗保健:GPT-4可用于医生和护士的培训,甚至作为辅助医疗诊断和治疗的工具。那岂不是把病人的命交给“机器人医生”了?对于“治疗方案二选一”的困扰,GPT-4说不定能给出“方案三”?
5)个性化客户服务:GPT-4可用作智能客服和虚拟助手,能够更加聪明地回答客户询问和提供有用的建议。听说一些不怎么理性的用户常常向虚拟助手发起“约会”,现在GPT-4都能拍拍它们的肩膀,说:“抱歉,我是个虚拟人物,你还是找真实的对象吧!”
当然,以上只是我们的猜测,未来GPT-4会如何被应用和颠覆,我们仍然等待着数不尽的创意者和发明家们拿出他们的招牌把戏。
 GPT-4就像是一个“万能工具人”,可以在许多领域扮演着各种角色。它可以作为销售顾问,给你的顾客送上说服力十足的“甜言蜜语”,让他们不得不为你掏腰包。而如果你特别挑剔,可以用GPT-4的客服代理和聊天机器人来解决你的各种问题。
GPT-4就像是一个“万能工具人”,可以在许多领域扮演着各种角色。它可以作为销售顾问,给你的顾客送上说服力十足的“甜言蜜语”,让他们不得不为你掏腰包。而如果你特别挑剔,可以用GPT-4的客服代理和聊天机器人来解决你的各种问题。
4)新闻:GPT-4可称之为“智能记者”或“垃圾新闻克星”,它可以帮你快速地瞬间拥有一手真实可信的新闻!而那些捏造和虚假报道的假新闻,GPT-4的“法眼”可不会放过。
5)医疗大健康:让医生和护士们可以轻松利用GPT-4的助手功能诊断和治疗各种疑难杂症。而对于那些身心俱疲的病人,GPT-4又可化身为治疗师和健康顾问,用最温暖的话语为患者提供精神和情感上的支持。
6)法律:GPT-4的口才在法律领域可是五星级的,它可以作为律师或法官的得力助手,帮助他们起草和审查许多法律文件和合同。即使你面对繁琐的条文和复杂的诉讼,有了GPT-4,你也不用再担心会“咕咕叫”了。
7)生命科学:GPT-4的生物分支就像一个“逆天专业户”,可以从合成数据到蛋白质折叠模型,帮你完成从药物发现到学术论文研究的所有工作。虽然还存在一些问题,但总体上GPT-4的潜力还是很大的,未来或许可以推动医疗保健的发展,让我们的健康更有保障。
不行”的时代即将来临,天啊!
2)借助GPT-4,供应链和物流领域拥有了更易操作、成本更低、性能和可持续性更高的生产模式。那些高昂的物流费用和高质量的产品,完全可以让GPT-4来帮忙打理,让我们终于可以“躺着也能挣钱”了啊!
3)GPT-4的强大功能还会在更多领域中被应用,让我们的工作变得更轻松,同时也可以创造更多更优质的内容。今天我们拿了GPT-4,未来我们就能“拿到手软”啦!
族的财富,还有一种无法估量的可能性。
2)AI技术的发展不是闹着玩的,GPT-4的应用也不是简单地“架个飞机”,而是要当心“机会成本”!未来可能会有很多“小学生也写AI”,但是那些没用的恶作剧都是过眼云烟,真正让我们受益的还是GPT-4这类技术。于是那些多余的繁琐工作,就可以让GPT-4给你轻松解决。而AI不会有情感,那些没被替代的自然情感,由人类持守,就像“公主和青蛙”,人才是你的灵魂啊!
3)现在的考核方式已经变成了好多人的噩梦。虽说知识很重要,但它绝不是我们唯一需要考虑的因素,拥有更全面的能力和实战经验同样是至关重要的。如果你还不拥有一些先进的机器技能,那么你就会“OUT”在这个领域里。不过别担心,相信有GPT-4这样的大模型陪伴,你也会成为一名顶尖的机器小能手。
这个“圣杯”两个字,就是那个打得不鸣则已、一鸣惊人的武器,有点像小学生考试遇到难题时突然“开挂”一样。不仅让人感叹神奇,也让我们产生了一些无法理解的想法。
相关文章