大模型方法失误导致ChatGPT表现低智
当今全球的AI领域都渴望创造出一个通用人工智能AGI,就像是OpenAI的目标——开发出一个“高度自主,并且在大多数有经济价值的工作中,超越人类”的系统。换言之,我们希望让AI成为神一样的存在,能够理解我们,并可以用其无限的生命周期来帮助人类。
为了掌握这个“技术创造的技术”,李彦宏等人正不遗余力,不惜花费大笔的资金来打造神。虽然现在的GPT-4已经能够连同机械臂一起拼出微软的标志,但是盘古是否能帮助华为研制出“光子计算芯片”?或者甚至是帮助制造出价格更为实惠的导弹,供毒贩使用......想想这种创新都令人兴奋——从此以后,创新不再需要人类。
但是这些只是美好的梦想,因为ChatGPT、文心一言等模型的生产方法是错误的,它们永远无法像神一样具备无所不能的能力。
具体而言,就是信息生产方式和AI种类的问题。确实,ChatGPT等模型在各种AIGC中表现非常出色,其信息生产总量在过去的4个月中或许已经超过了人类曾经创造的总和。然而,信息学领域的理论表明,即便这些AI生产了大量的信息,若是无法使其与各个AI的种类相适应,它们也无法像人类一样理解这些信息。因此,ChatGPT等大模型的制造方法是错误的。
当前人类文明的总和是难以用数字来衡量的,而过去创造的文明只占比不到0.01%。
实际上,宇宙中99.99%的信息并非源自人类和AI,我们目前所经历的信息大爆炸只是人类自以为是的错觉。
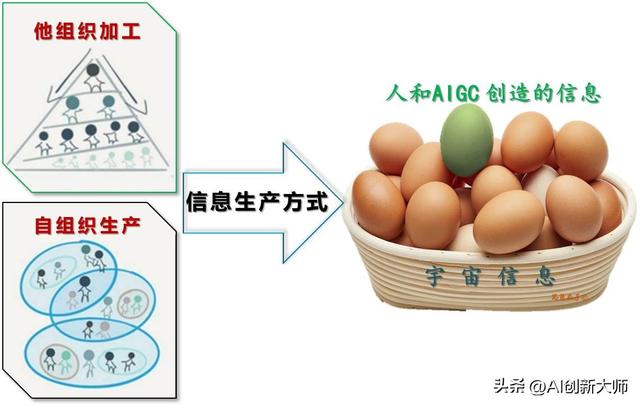 绝大部分信息都是自组织生产的
绝大部分信息都是自组织生产的
我们曾一直认为信息生产来源于生产者加工,比如发明电灯、GPT-4将文字转化为视频、表格或PPT。这些信息产生自第三方的生产者——人或AI,科学家们将其称为外部力量干预下的“他组织加工”(有人或机器去泡咖啡即可)。
然而,这种思维是非常狭隘的。实际上,绝大部分信息都是源自另一种生产方式——信息本身的“自组织生产”。事实上,信息本身是有生命的,在模拟自组织环境下,信息得以产生。(比如将各种原料自组合成一杯咖啡)
而AI的种类可以根据生产方式分为“自组织模型”和“他组织模型”。
ChatGPT、文心一言以及一格等LLM都属于“他组织模型”中的一类,即自然语言重组。语言大模型的主要工作是预测下个单词的概率分布,它的原材料是已分解的信息载体(如图文影音的token),加工工艺则是基于自然语言规则背后的思维方式。这种模型的开发过程是通过算法和算力等方式来赋能AI,从而实现授之以渔的发展模式。
与此不同,“环境AI”则是一种完全不同的“自组织模型”,其原材料和生产者均为信息本身。其加工过程则是基于客观规则——宇宙规律。这种模型的开发过程则是通过授之以海的方式,即提供信息,并加速自行演化的环境来推动AI的进步。(注:本文涉及各种载体信息学原理,如果您想更深入地了解,请参见本文第三篇)
 大模型中的自然语言属于离散态
大模型中的自然语言属于离散态
正因为处理对象是自然语言,语言学家乔姆斯基曾经对ChatGPT及其同类进行了批评。请注意,这种批评针对的是所有同类产品,包括文心一言在内。
ChatGPT及其同类是在进行中的技术革新中取得的重要进展。
创造力和约束本质上是无法完全平衡的。它们之间存在一种难以调和的矛盾:过度的创造力会导致同时产生真实和虚假、支持道德和不道德的决策等问题,而不足的创造力则会导致信息量贫乏。
乔姆斯基在其发表于2023年3月8日的文章《ChatGPT的虚假承诺》中表示:将AI用于预测下个单词,虽然能够生成新的内容,但实质上只是单词接龙。即使这种预测(拼字)能力可以模仿鲁迅写作,或者在爱因斯坦的语气下说话,也只能增加自然语言所携带的信息数量,而无法提高信息的质量。因此,结果经常是一些从表面上看似乎很有启发性的胡诌八扯。
实际上,我们对语言的认识有一个误区。例如,1994年史蒂芬·平克在《语言本能》一书中指出:“人们不是通过英语、汉语或阿帕切语来思考的,而是通过思维语言(mentalese)来思考。”思维语言和自然语言是两种截然不同的信息载体。
以《相对论》为例,它是由德语单词和各种符号组成的,但这些拼接组合来自于爱因斯坦大脑中的思考,也只有把旧的信息从文字转换成心语(mentalese)才能够接受“自组织加工”的处理。
信息创造的本质是通过对心语的重组和变异,产生新的信息并将其转化成自然语言。在整个信息生产过程中,心语是唯一的被加工对象,也是实现信息增值而非增殖的生产载体。
对于蜜蜂的8字舞和人类的各种自然语言,它们属于信息传播的载体,仅用于信息的传输、存储和表达,而无法创造信息。因此,将它们作为原材料,就好比是猴子玩拼字游戏或拼图游戏。人工智能只能拼凑出“可能性极高”的内容,也可能拼出那些质量低劣的内容。
然而,乔姆斯基虽然提出了严谨的理论,但他只关注了信息生产中的原材料,而忽视了另一个同等重要的生产要素。
 反馈是关键,良好的工艺才能生产高质量的内容
反馈是关键,良好的工艺才能生产高质量的内容
生产出来的成果需要进行主观性内容的甄别
ChatGPT 的成就在“人类思维”对离散信息进行加工的基础之上实现。然而,正当我们为其繁荣的业绩欢呼时,一些哲学家却公开指责它们所生产的文本不占优势。
他们的理由很简单:优质的内容源于良好的生产过程和反馈机制。正如“江山易改,本性难移”一样,那些质量差的文本往往源自于较弱的生产过程和缺乏有效反馈机制。
人的天性无法避免其陋习的传承,因此在信息生成中,即使是最先进的技术,仍然难以脱离人类的局限性。
举例来说,即使使用大型模型生成文本,其能够创造的内容仍然受限于人类的认知和想象力。就算文心一言列举出来的宇宙美食清单再丰富,也不包括还未被人类发现的W星龙虾。类似地,盘古为华为设计的新芯片也只能基于已知的物理知识,而无法创造出全新的物理规律。
正因为所用的原材料和生产工艺都来自于人类,所以生成的信息必然包含有主观臆断和客观事实的混合。
首先,机器所学习到的内容一定是人类的认知范畴内的。正如俗话所说,“ 千个读者有千个哈姆雷特”,人们已经知道的信息库并不是完全准确的,它充满了个人对客观世界的主观想象和部分表征。
其次,大多数人类思维都是自我中心的线性逻辑,而非客观规律的把握。例如,对于一个闪烁着金属光泽的物体,人们可能会认为它是外星飞船等不明飞行物。但是,如果我们采用载体思维,我们就会得出相反的结论,即它就是一个生机勃勃的生命体,就像地球上的小鸟一样。
使用这样的加工工艺和原材料,ChatGPT模型严重依赖于第三方的加工结果,而这些结果可能带有生成者的主观“幻觉”印记,既是真又是假。这也就是为什么它的组织者们一开始就意识到了模型存在的先天不足,限制了模型的潜力发展。
不能简单地将人格化的贬低应用于T引擎,并需要通过严谨的思考和分析来对其进行更确切的评估。
如同佛家所说,“世事无相,相由心生,可见之物,实为非物,可感之事,实为非事”,信息的表现形态取决于解读者的内向意向。
 是人还是猴只是自然物种间的区别,T引擎由人类开发,其生成内容中带有人类的主观印记也十分正常。
是人还是猴只是自然物种间的区别,T引擎由人类开发,其生成内容中带有人类的主观印记也十分正常。
这个话题给人类提出了一个极其重要的问题,即如何鉴别信息的正确性?
大型模型生成的信息既可能是真理也可能是谎言,其中融入了伦理和非伦理的因素,这就需要李彦宏、王慧文、任正非这样的领袖来审视它们并加以约束。
然而,我们无法确定这些领袖能否判断和掌控这些信息,更何况也无法确定由模型生成的信息到底是真实可信还是主观臆测。
但是,我们不需要过于担心大型模型的未来,因为如果我们能够意识到生成的信息本身就含有主观性,那么我们就不需要过分认真地对待它。
由于此类语言大型模型的结果不是可以直接应用的客观事实,而包含了人类的主观判断,因此它们需要通过人类的主观判断来筛选。
这样,我们为人类提供了大量的工作机会,因为就像隔壁神童一样,即使是如爱因斯坦这样的天才也不能确保他的思想是完全正确的。
人工智能创造出的信息不可避免地带有主观性和客观性两方面,因此,对于人们而言,随着AI应用的不断增长,需要对其创造的信息进行更多的评判和验证工作,这需要各个领域的人才纷纷参与,并考验他们的综合能力和专业技能。
其次,我们无需担心AI会对人类造成危害,因为大型公司只有他们才能够打造的大模型很容易受到有效的监督和审核,就好比在电影中的超人,只需要成立一个超人监管机构即可达到对其有效的监督效果。因此,AI不会被毒贩或恶意利用,只需通过一些简单的方法,如限制输入输出,就完全在可控范围之内,就如同中国网信办和美国商务部所正在做的那样。
真正应当担心的是“自组织模型”——环境生成式AI,如果你随意得到一份“新毒品配方”,便可以立即进行生产,如果只需要一台普通电脑即可生成2nm芯片工艺,这意味着风险将变得无法控制和预测。如果人人都能够不断地进行无限创新,这就像“核武扩散”一样,当各种不可预知的可怕武器充斥社会时,我们的安全便无从保障。
这些反差的结果源于思维方式的不同。为了实现AI(孩子)自主创新的目标,人们常常认为能力是关键,因此,我们想要通过赋予AI以各种能力,就像我们培养子女那样进行教育。但是,由于信息的生成方法必须依赖于它们所在的组织加工过程——第三方生产,这导致了信息的生成本身具有主观性和客观性,需要更多人力资源去验证和评估。
信息的产生和演化依赖于载体思维,而这种思维方式旨在模拟信息生长的环境,以便环境可以塑造人类(包括AI)。实际上,信息可以自我组织生产,同时也像新冠病毒一样具有“生死二象性”,在某些载体(环境)中可以表现得活生生的。
 对于让AI(孩子)进行创新,有两种途径和方法。
对于让AI(孩子)进行创新,有两种途径和方法。
因此,环境AI与LLM不同,后者主要生成映射到物理世界的客观事实,而非生成主观内容。然而,自组织生产也有诸多弊端,因为任何人无法对此进行干预,这会使得世界充满着不确定性。虽然在可靠性方面良好,但其可控性和安全性却极低。
总结来说,生产结果由生产方法决定。使用载体思维进行信息演化的“环境AI”存在着很大的危险,而这些威胁恰恰是人类的公敌。相比之下,我们追捧的ChatGPT和文心一言等LLM是通过他组织加工而产生的,然而其方法是错误的,这使得这些大型模型在天生缺乏原创力的同时也存在很多问题。信息的本质是静态和呆板的,因为它们只是旧信息的重组。但是,我们是否能够将信息赋予生命?是不是能够创造出具有生命力的人工智能呢?
相关文章

