
用更少GPU完成更多计算量中文巨量模型源10比GP
机器之心原创
编辑:杜伟
语言大模型的终极目标是什么?
在自然语言处理(NLP)领域,暴力美学仍在延续。
自 2018 年谷歌推出 BERT(3.4 亿参数)以来,语言模型开始朝着「大」演进。国内外先后出现了参数量高达千亿甚至万亿的语言模型,比如谷歌的 T5(110 亿)、OpenAI 的 GPT-3(1,750 亿)、智源研究院的 WuDao2.0(1.75 万亿)……
有人不禁会问,语言模型的参数越来越大,它们究竟能做些什么,又智能到什么程度了呢?
9 月 28 日,浪潮人工智能研究院推出了中文巨量语言模型——源 1.0,让我们看到了语言模型超强的创作能力。
除了轻松应对大多数语言大模型都能完成的对话、故事续写、新闻生成和接对联等任务,源 1.0 还具备风格约束的诗歌创作能力,比如给出李白、杜甫或诗经风格的诗句,模型便能输出相应风格的诗句。堪称诗界的百变大师!
 不仅如此,源 1.0 还具备强大的模仿能力,输入一个不存在的词语以及给出它的定义和示例。模型便能依葫芦画瓢,造出符合这个词语定义、逻辑和语境的语句。
不仅如此,源 1.0 还具备强大的模仿能力,输入一个不存在的词语以及给出它的定义和示例。模型便能依葫芦画瓢,造出符合这个词语定义、逻辑和语境的语句。
 源 1.0 到底有多强大?
源 1.0 到底有多强大?
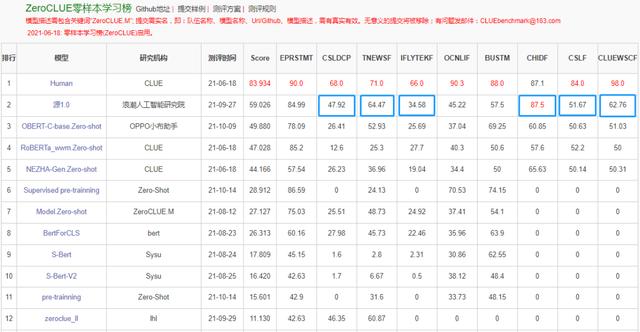
2,457 亿参数、5TB 高质量中文数据集、2,128 张 GPU 上训练 16 天……,这些都为源 1.0 强大的语言智能打好了基础。源 1.0 也不负众望,在中文语言理解测评基准 CLUE 中取得了优异的表现。
在 ZeroCLUE 零样本学习榜中,源 1.0 在文献分类(CSLDCP)、新闻分类(TNEWSF)、长文本分析(IFLYTEKF)、成语阅读理解(CHIDF)、文献摘要识别(CSLF)和名词代词关系(CLUEWSCF)六项任务上摘得榜首。其中,在成语阅读理解单项任务上甚至超越了人类水平。
 刷榜只是语言模型性能强弱的一个侧面体现,源 1.0 的创作能力在对话、故事、新闻、诗歌和对联等多样性场景中得到了进一步验证。在这些场景任务中,浪潮创建了一场「图灵测试」,用于比较源 1.0 模型生成的文本与人类创作的真实文本,并分辨出这些文本哪些「由模型生成」哪些「由人类创作」。
刷榜只是语言模型性能强弱的一个侧面体现,源 1.0 的创作能力在对话、故事、新闻、诗歌和对联等多样性场景中得到了进一步验证。在这些场景任务中,浪潮创建了一场「图灵测试」,用于比较源 1.0 模型生成的文本与人类创作的真实文本,并分辨出这些文本哪些「由模型生成」哪些「由人类创作」。
具体地,浪潮任意选择了源 1.0 生成的 24 篇文章,包括 4 副对联、5 首中文传统和现代诗歌、5 篇新闻文章、5 个故事和 5 段对话。其中,对联、诗歌和对话的创作被视为短文本任务,新闻和故事生成被视为长文本任务。与这些对比的人类创作的文章出自名家所作的诗歌、经典小说、搜狐新闻的新闻文章和 LCCC-large 数据集中的对话。对此,浪潮共收集了 83 份有效问卷。
结果显示,源 1.0 生成的文章只有 49.16% 的概率被正确识别为「由模型生成」,这意味着受访者难以区分人类和模型生成的文章,尤其是在对话和新闻生成这两个场景,误判率分别为 54.32% 和 57.88%。不过可以看到,由于源 1.0 的预训练语料中没有加强古汉语,源 1.0 在诗歌和对联生成场景表现相对不佳,但仍具备生成带有一定格式和格律的文本的能力。
 目前,源 1.0 能够生成多种高质量的文本,如对话、新闻稿件、故事续写等。对于这些类别的任务,模型生成的文本与人类创作的内容相差无几,甚至达到了以假乱真的程度。
目前,源 1.0 能够生成多种高质量的文本,如对话、新闻稿件、故事续写等。对于这些类别的任务,模型生成的文本与人类创作的内容相差无几,甚至达到了以假乱真的程度。
先以如下对话场景为例,受访者正确分辨出「由模型生成」答案的概率仅为 38.28 %,这意味着源 1.0 在对话任务上做到了非常情景化,回答也接近人的讲话风格。
 再来看新闻生成场景,给出摘要,然后续写正文,受访者正确分辨出「由模型生成」新闻的概率为 34.15 %。源 1.0 生成的文本不仅较人类撰写的篇幅更多,显然也更符合新闻用语环境。
再来看新闻生成场景,给出摘要,然后续写正文,受访者正确分辨出「由模型生成」新闻的概率为 34.15 %。源 1.0 生成的文本不仅较人类撰写的篇幅更多,显然也更符合新闻用语环境。
 但应看到,源 1.0 等大模型的应用场景绝对不会止步于此。12 月 11 日,机器之心举办了 NeurIPS MeetUp China,浪潮信息副总裁、人工智能 高性能计算 (AIHPC) 产品线总经理刘军做了主题为《AI 大模型时代的浪潮思考与实践》演讲。他认为,未来大模型还将可能在更多应用场景中发布作用,如运营商文本类日志和报告的提取和总结、元宇宙中 AI Robot 的语言生成、理解和对话等。
但应看到,源 1.0 等大模型的应用场景绝对不会止步于此。12 月 11 日,机器之心举办了 NeurIPS MeetUp China,浪潮信息副总裁、人工智能 高性能计算 (AIHPC) 产品线总经理刘军做了主题为《AI 大模型时代的浪潮思考与实践》演讲。他认为,未来大模型还将可能在更多应用场景中发布作用,如运营商文本类日志和报告的提取和总结、元宇宙中 AI Robot 的语言生成、理解和对话等。
语言大模型的极限在哪里?目前似乎没有哪家科技企业能够清楚地指明。浪潮的源 1.0 中文巨量语言模型,在探索 AI 拟人能力这条路上走出了坚实的一步。
最后,对刘军演讲内容感兴趣的读者,请戳以下视频:
https://v.qq.com/x/page/e3314u8y1l3.html
相关文章

