大模型battleLLM排行榜出炉清华竟位列第五
【CSDN 编者按】自GPT爆火之后,当下流行的开源大型语言模型越来越多,LMSYS 组织(UC伯克利博士Lianmin Zheng牵头举办)建立了 Chatbot Arena 基准平台通过匿名随机竞争来评估他们,随后发布
Elo 等级排行榜,排行榜至现在仍在定期更新,期待更多的用户贡献模型,进行投票,开发者们也可以参与进来!作者 LMSYS 组织
译者|陈静琳 责编 屠敏
出品 CSDN(ID:CSDNnews)
开源大模型太多?
LMSYS Org 直接建立了一个竞技场,以众包方式让他们匿名、随机的进行对抗,形成排行榜。并邀请整个社区加入这项工作,贡献新模型,所有人都可以参与提问和投票来评估它们,到底谁是你心目中的 NO.1 !
大模型们直接进行比拼(图1),就像下图中,模型 B 完美说出正确答案,而模型 A 牛头不对马嘴,遗憾出局。
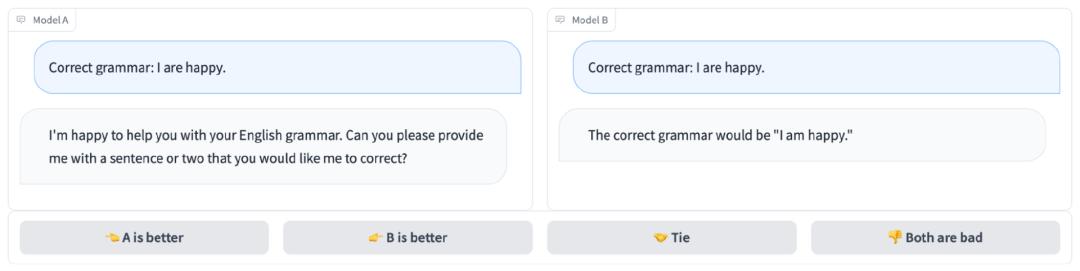 图 3:前 15 种语言的战斗计数
图 3:前 15 种语言的战斗计数
还有,在所有数据中描绘了语言分布,显示大多数用户提示都是英语。
 玩家的评分可以在每场战斗后线性更新。假设玩家 A(具有 Rating Ra)被期望得分 Ea 但实际得分 Sa 。更新玩家评分的公式是:
玩家的评分可以在每场战斗后线性更新。假设玩家 A(具有 Rating Ra)被期望得分 Ea 但实际得分 Sa 。更新玩家评分的公式是:
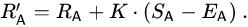 使用收集到的数据,计算了该笔记本中模型的 Elo 评分,并将主要结果放在表 1 中。欢迎大家自己尝试使用投票数据来计算评分。并且,数据只包含投票结果,没有对话历史,因为公开对话历史会引起隐私和病毒等担忧。
使用收集到的数据,计算了该笔记本中模型的 Elo 评分,并将主要结果放在表 1 中。欢迎大家自己尝试使用投票数据来计算评分。并且,数据只包含投票结果,没有对话历史,因为公开对话历史会引起隐私和病毒等担忧。
 双赢率作为校准的基础,LMSYS 组织还展示了锦标赛中每个模型的成对获胜率(图 4)以及使用 Elo 评级估算的预测成对获胜率(图 5)。通过比较数据,发现 Elo 评级可以相对较好地预测胜率。
双赢率作为校准的基础,LMSYS 组织还展示了锦标赛中每个模型的成对获胜率(图 4)以及使用 Elo 评级估算的预测成对获胜率(图 5)。通过比较数据,发现 Elo 评级可以相对较好地预测胜率。
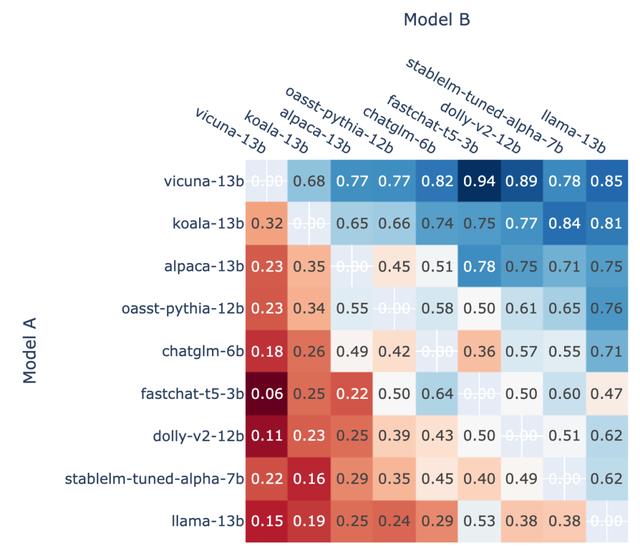 图 4:模型 A 在所有非平局 A 与 B 战斗中获胜的比例。
图 4:模型 A 在所有非平局 A 与 B 战斗中获胜的比例。
 图 5:在 A 对 B 战斗中使用模型 A 的 Elo 评级预测胜率
图 5:在 A 对 B 战斗中使用模型 A 的 Elo 评级预测胜率
![]() 未来的计划LMSYS 组织计划在以下项目上开展工作:
未来的计划LMSYS 组织计划在以下项目上开展工作:
添加更多闭源模型(ChatGPT-3.5 现已在匿名竞技场可用)
添加更多开源模型
发布定期更新的排行榜(例如,每月)
实施更好的采样算法、锦标赛机制和服务系统以支持更多模型
提供不同任务类型的细粒度排名。
希望所有用户能进行反馈,以使竞技场变得更好。LMSYS 组织邀请整个社区通过贡献各自的模型并为能提供更好答案的匿名模型投票来加入这项基准测试工作。参与者可以访问 https://arena.lmsys.org 为更好的模型投票。如果想在竞技场中查看特定模型,可以按照指南(https://GitHub.com/lm-sys/FastChat/blob/main/docs/arena.md#how-to-add-a-new-model)添加它。
演示:https: //arena.lmsys.org
排行榜:https: //leaderboard.lmsys.org
GitHub: https://github.com/lm-sys/FastChat
Colab 笔记本:https://colab.research.google.com/drive/1lAQ9cKVERXI1rEYq7hTKNaCQ5Q8TzrI5 ?usp=sharing
相关文章